- Wstęp
- -
- Znane metody
- -
- Opracowane procedury
- -
- Instrukcja obsługi procedur
- -
- Literatura
- -
Jak już zostało napisane we wstępie, istnieje sporo metod graficznego przedstawiania punktów przestrzeni wielowymiarowej na płaszczyźnie. Wykresy są z założenia dwuwymiarowe. Dlatego potrzeba pewnej pomysłowości, aby pokazać zależności między trzema a nawet większą liczbą zmiennych na płaszczyźnie, tak kartki papieru jak i ekranu monitora. Wszystkie wykresy wielu zmiennych wymagają zmiany lub rozszerzenia znanych metod wizualizacji, jakie używamy w przypadku dwóch zmiennych, co spowodowało wymyślenie wielu metod. Często opłaca się zastosować kilka z nich do jednego zestawu danych. W praktyce, największe zastosowanie znalazły następujące metody:
- Rzutowanie Prostokątne ([16],[6])
- Głównych Składowych ([16],[6])
- Głównych Współrzędnych ([16],[6])
- Współrzędnych Dyskryminacyjnych ([16],[6])
- Grand Tour ([1],[3],[8],[10])
- Glyph Plots ([10],[17])
- Draftsman's Plot zwana inaczej Scatter Plot Matrices ([10],[5],[9])
- Brushing ([2])
- Stars Plots ([10],[4])
- Biplot ([16],[10],[11],[12])
- Metoda Rzutowania Prostokątnego
Metoda ta jest najczęściej stosowana w geometrii przy przedstawianiu rzutów elementów przestrzeni trójwymiarowej na płaszczyźnie. Polega ona na zmniejszeniu liczb wymiarów poprzez wykonanie rzutu prostokątnego elementu na jedną z płaszczyzn wyznaczonych przez osie globalnego układu współrzędnych. Metoda ta została już omówiona ([6]) , dlatego nie będę się nią zajmował.
- Metoda Głównych Składowych
Jej autorem jest H. Hotelling ([14]). Polega ona na liniowej transformacji wektora zmiennych X w parę zmiennych Z1 i Z2. Należy przy tym dążyć do uzyskania ekstremum funkcji charakteryzującej dobroć przedstawienia. Aby spełnić powyższy warunek wektory określające współczynniki kombinacji liniowych, czyli składowych głównych, powinny być wektorami własnymi odpowiadającymi dwóm największym wartościom własnym macierzy kowariancji zbioru obserwacji. Metoda ta została już omówiona ([6]), dlatego nie będę się nią zajmował.
- Metoda Głównych Współrzędnych
Metoda ta, opracowana przez J.C. Gower'a ([13]), częściowo łączy się z metodą głównych składowych. Prowadzi ona mianowicie również do przybliżania kwadratów odległości pomiędzy danymi w przestrzeni m-wymiarowej kwadratami odległości na płaszczyźnie. Tym co różni ją od w/w metody jest fakt, iż mogą tu zostać wykorzystane dowolne miary odległości, a nie tylko euklidesowa, jak to miało miejsce w analizie głównych składowych. Metoda ta została już omówiona ([6]), dlatego nie będę się nią zajmował.
- Metoda Współrzędnych Dyskryminacyjnych
Jej głównym zadaniem jest przedstawienie na płaszczyźnie danych w taki sposób, aby jak najlepiej odzwierciedlić różnice pomiędzy klasami, a nie pomiędzy poszczególnymi danymi. Metoda ta została już omówiona ([6]), dlatego nie będę się nią zajmował.
- Metoda Grand Tour
Metoda Grand Tour jest to metoda polegająca na oglądaniu danych wielu zmiennych "ze wszystkich stron". Po raz pierwszy zaproponował ją D. Astimov w 1985 roku ([1]), a składa się na nią animacja obrazująca dane. Obserwatorowi zostaje zaprezentowana ciągła sekwencja d-wymiarowych obrazów p-wymiarowych danych. Wymiar obrazu może być równy 1,2,3,...,p. Jak na razie implementacje tej metody można spotkać w programach XGobi ([19]) oraz XLispStat ([19]) dostępnych w sieci Internet na zasadach Freeware.
Poniżej znajdują się przykłady powyższej metody działającej na danych, wygenerowanych przez umieszczenie punktów na wierzchołkach 9-wymiarowej kostki (Rys.1 - 5). Stanowią one dziewiczą formę metody zaproponowanej przez Astimov'a w 1985 roku. Są to zwykłe sekwencje video, bez możliwości ingerencji ze strony użytkownika. Aby je zobaczyć, należy kliknąć myszą w odpowiedni obrazek, co spowoduje otwarcie okna z animacją.
- 1 wymiar (sekwencja histogramów)
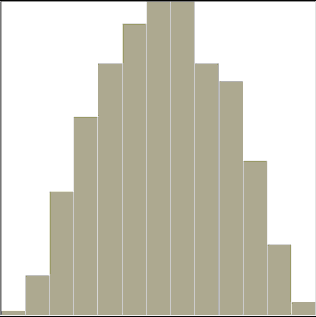 Rys.1 Przykład zastosowania metody Grand Tour dla przedstawienia jednego wymiaru
Rys.1 Przykład zastosowania metody Grand Tour dla przedstawienia jednego wymiaru - 2 wymiary (scatterplot)
 Rys.2 Przykład zastosowania metody Grand Tour dla przedstawienia dwóch wymiarów
Rys.2 Przykład zastosowania metody Grand Tour dla przedstawienia dwóch wymiarów - 3 wymiary
 Rys.3 Przykład zastosowania metody Grand Tour dla przedstawienia trzech wymiarów
Rys.3 Przykład zastosowania metody Grand Tour dla przedstawienia trzech wymiarów - 4 wymiary
 Rys.4 Przykład zastosowania metody Grand Tour dla przedstawienia czterech wymiarów
Rys.4 Przykład zastosowania metody Grand Tour dla przedstawienia czterech wymiarów - 5 wymiarów
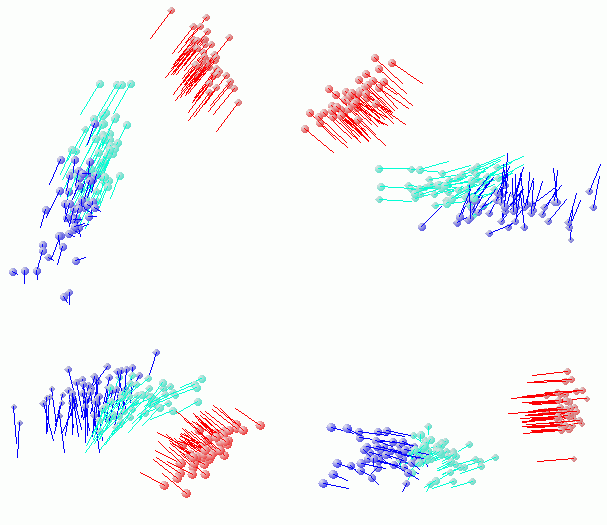
 Rys.5 Przykład zastosowania metody Grand Tour dla przedstawienia pięciu wymiarów
Rys.5 Przykład zastosowania metody Grand Tour dla przedstawienia pięciu wymiarów - Metoda Glyph Plots
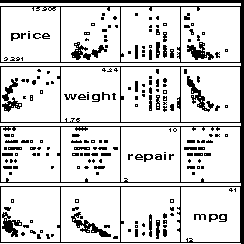
Najprostsze rozwinięcie metody rysowania punktów na płaszczyźnie polega na wybraniu dwóch głównych zmiennych dla naszego wykresu, i przedstawienie dodatkowych zmiennych przy pomocy symbolu glyph, użytego do narysowania każdej obserwacji. Dodatkowe zmienne mogą być pokazane przy pomocy takich właściwości jak: rozmiar, kolor, kształt, długość oraz kierunek linii. Metoda ta zapewnia względnie łatwy sposób projektowania swoich własnych symboli glyph. Poniżej (Rys.6) prezentowane są cztery różne widoki pochodzące z animacji wykonanej z użyciem języka Java. Aby ją obejrzeć wystarczy kliknąć myszą na obrazku, a otworzy się okno z animacją.
Rys.6 Cztery różne widoki dla wykresu czterowymiarowych danych "Irysy" przy wykorzystaniu języka Java ([15])Zastosujmy tę metodę dla danych dotyczących CENY, WAGI, zużycia paliwa i innych wartości wielkości i osiągów 74 samochodów. Wykres pokazany na poniższym rysunku (Rys.7) przedstawia zależności pomiędzy WAGĄ i CENĄ samochodów na tle innych zmiennych. Zgodnie z tym, co zostało wcześniej napisane, długość linii od każdego punktu jest proporcjonalna do zużycia paliwa, liczba kilometrów na galon (MPG), podczas gdy kąt względem poziomu jest proporcjonalny do oceny kosztów napraw. Region pochodzenia każdego modelu samochodu jest zakodowany na wykresie przy pomocy kształtu i koloru symbolu.
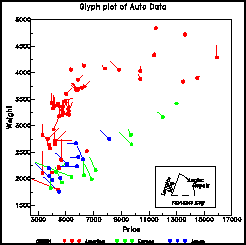 Rys.7 Wykres metodą Glyph dla danych AUTO
Rys.7 Wykres metodą Glyph dla danych AUTO - Metoda Draftsman's Plot zwana inaczej Scatter Plot Matrices
Metoda Glyph Plots jest skuteczna przy przedstawianiu trzech do pięciu zmiennych, jednak nie generalizuje tak łatwo większej liczby zmiennych. Dlatego powstała metoda scatterplot matrix, która może być wykorzystywana dla większej liczby zmiennych. W tej metodzie dane o więcej niż dwóch wymiarach, są przedstawione jako seria dwuwymiarowych wykresów zwanych serią paneli wykresów. Czasami niektóre informacje przepadają, kiedy znikają pozostałe wymiary, ale zazwyczaj zyskujemy o wiele więcej kiedy narysujemy cztery, pięć a nawet sześć zmiennych na raz. Nowoczesne oprogramowanie statystyczne jest zazwyczaj zdolne wykonać takie wykresy dla więcej niż trzech zmiennych i więcej niż dwóch klas punktów. Z takich wykresów można odczytać, które zmienne są powiązane, a które nie. Każdy panel (wykres) w metodzie Scaterplot Matrix jest identyfikowany przez numer jego szeregu i kolumny w macierzy wykresów. Np. panel leżący w lewym-górnym rogu macierzy przedstawionej na poniższym rysunku (Rys.8), jest identyfikowany jako (1,3), a w prawym-dolnym jako (3,1). Puste panele na przekątnej oznaczają nazwy zmiennych. Panel (2,1) jest wykresem parametru X względem Y, podczas gdy panel (1,2) na odwrót, tzn. Y względem X. W tej metodzie wszystkie zmienne są traktowane identycznie. Główną ideą jest wizualne połączenie cech z jednego panelu z cechami w innych panelach. Sposób pokazywania paneli jest specjalnie tak zaprojektowany, aby zwiększyć efekt wizualnego połączenia. Ta technika jest jeszcze bardziej czytelna, dzięki zastosowaniu linii pomocniczych w postaci siatki. Wzór, jaki tworzą punkty może być rozpoznany w obu kierunkach : poziomym i pionowym. Pomimo popularności tej metody, nikt nie zna tożsamości oryginalnego twórcy.
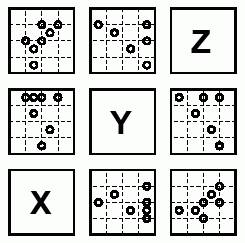 Rys.8 Macierz wykresów przedstawia dane z trzema zmiennymi X, Y i Z.
Rys.8 Macierz wykresów przedstawia dane z trzema zmiennymi X, Y i Z.Rozpatrzmy te same dane, co w metodzie glyph. Poniższy przykład (Rys.9) pokazuje zależności między zmiennymi CENA, WAGA, MPG i NAPRAWY w danych AUTO. Region pochodzenia jest określony przez symbol.
Na wykresie widzimy: umiarkowanie silne (niepożądane) korelacje między MPG a CENĄ i WAGĄ
samochody o większej wytrzymałości wydają się mieć lepsze wskaźniki kosztów NAPRAW i są w większości produkcji Japońskiej
pozytywna relacja między CENĄ i WAGĄ dla wszystkich regionów pochodzenia (gdzie amerykańskie modele są cięższe)
zależność pomiędzy CENĄ i NAPRAWAMI jest skomplikowana i prawdopodobnie nieliniowa
 Rys.9 Macierz wykresów dla danych AUTO. Amerykańskie modele : kółka, Europejskie : kwadraty, Japońskie : gwiazdki.
Rys.9 Macierz wykresów dla danych AUTO. Amerykańskie modele : kółka, Europejskie : kwadraty, Japońskie : gwiazdki.- Metoda Brushing
Metoda ta została po raz pierwszy zaprezentowana przez Richard'a A. Becker'a i William'a S. Cleveland'a ([2]). Jest ona bezpośrednim rozwinięciem metody Scatter Plot Matrices. Są dwa sposoby stosowania tej metody na macierzach wykresów: opisywanie i zaawansowane łączenie. Opisywanie polega na tym, że po najechaniu wskaźnikiem myszy na konkretną część wykresu, pojawia się okienko z opisem. W zaawansowanym łączeniu wskaźnik ma kształt prostokąta o zmiennych wymiarach. Przy jego pomocy można zaznaczyć jakiś wybrany obszar punktów w wybranym panelu. Poniższy rysunek (Rys.10) pokazuje taką sytuację z zaznaczonym obszarem w panelu (3,2). Dane w zaznaczonym obszarze są widoczne jako "+" zamiast "o".
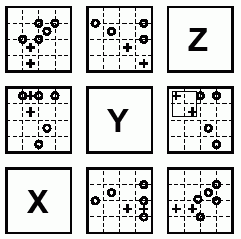 Rys.10 Zaawansowane łączenie z kwadratowym zaznaczeniem w panelu (3,2).
Rys.10 Zaawansowane łączenie z kwadratowym zaznaczeniem w panelu (3,2).Takie same zmiany zostają zastosowane na, odpowiadającym tym danym, punktach w pozostałych panelach. Patrząc na różne panele i porównując wynik w poziomie i pionie, dzięki tej metodzie dostajemy do ręki potężne narzędzie do analizy wielowymiarowych danych w macierzach wykresów. Więcej metod stanowiących rozwinięcie i uzupełnienie metody Draftsman's Plot można znaleźć ([7]).
- Metoda Star Plots
Jest to dobra metoda ([10],[4]), aby zaprezentować obserwacje wielowymiarowe z dowolną liczbą zmiennych. Każda obserwacja jest reprezentowana przez wykres, kształtem przypominający gwiazdę (stąd nazwa Star Plots), w którym każdy promień przedstawia jedną zmienną. Dla danej obserwacji, długość każdego promienia jest proporcjonalna do wielkości odpowiedniej zmiennej. Metoda ta różni się od metody Glyph Plots tym, że wszystkie zmienne są użyte do konstruowania wykresów - gwiazd, nie ma tu podziału na zmienne pierwszo- i drugorzędne. Zamiast tego, wykresy - gwiazdy są przedstawiane na ekranie, jako ułożony w prostokąt zestaw kolejnych obserwacji. Łatwiej jest zauważyć schemat w zestawie danych, kiedy obserwacja jest przedstawiona w jakimś nie arbitralnym porządku, i kiedy zmienne są przyporządkowane do promieni gwiazdy w jakiejś zrozumiałej i sensownej kolejności.
Poniższy przykład (Rys.11) przedstawia taki wykres dla 12 numerycznych zmiennych dla danych AUTO.
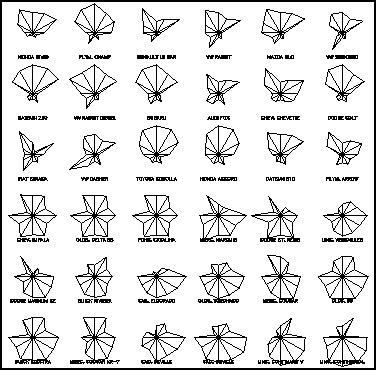 Rys.11 Star plot dla danych AUTO. Każda gwiazda reprezentuje jeden model samochodu, każdy promień jest proporcjonalny do jednej zmiennej.
Rys.11 Star plot dla danych AUTO. Każda gwiazda reprezentuje jeden model samochodu, każdy promień jest proporcjonalny do jednej zmiennej.Te 12 zmiennych jest zaaranżowanych wokół centralnego punktu według poniższego schematu (Rys.12).
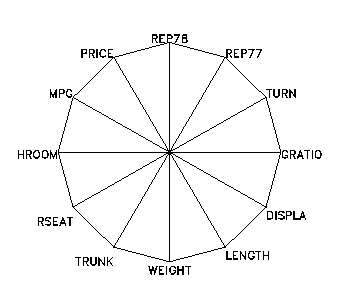 Rys.12 Schemat aranżacji promieni. Zmienne po bokach i na dole są związane z wagą, pozostałe z ceną i osiągami.
Rys.12 Schemat aranżacji promieni. Zmienne po bokach i na dole są związane z wagą, pozostałe z ceną i osiągami.Ta metoda jest szczególnie użyteczna, kiedy wszystkie zmienne mają taki sam wymiar. Dzięki temu, wzrost wartości ma podobne znaczenie dla wszystkich zmiennych. Dla danych AUTO oznacza to, że duże wartości zmiennej powinny oznaczać "lepszy" samochód i być prezentowanymi przez dłuższe promienie. Jak widać na wykresie (Rys.11) dominującym schematem w dwóch pierwszych rzędach jest gwiazda z dłuższymi promieniami na górze (dobra cena i osiągi) i krótszymi na dole (zmienne rozmiar), podczas gdy odwrotność tego stanu jest prawdziwa dla cięższych modeli w dolnych rzędach. Należy zwrócić uwagę, że na wykresach - gwiazdach chcemy zauważyć własności konfiguracji zebranych zmiennych reprezentowanych przez każdą obserwację, i że naszą interpretację ma wpływ rozłożenia zmiennych wokół centralnego punktu i ułożenia gwiazd na ekranie. Inne ułożenia mogą prowadzić do spostrzeżenia innych cech zestawu danych, więc wydaje się wskazane wypróbować inne alternatywy.
- Metoda Biplot
Wcześniej opisane metody: Scatterplot Matrices, Glyph Plots, Star Plots; wszystkie skupiają się na obserwacjach i domyślnie, na przedstawieniu zależności między zmiennymi. Metoda Biplot, zaproponowana przez K. R. Gabriel'a (1971;1981) ([11],[12]) przedstawia obserwacje i zmienne na tym samym wykresie, w sposób, który opisuje ich wzajemne zależności. Biplot bazuje na pomyśle, że każda macierz danych Y (n x p), może być przedstawiona w przybliżeniu w d wymiarach (gdzie d jest zazwyczaj równe 2 lub 3) jako produkt dwóch macierzy A (n x d) i B (p x d). Rzędy macierzy A reprezentują obserwacje w dwu- lub trzywymiarowej przestrzeni, a kolumny macierzy B reprezentują zmienne w tej samej przestrzeni. "Bi" w nazwie Biplot wywodzi się z faktu, że obie: obserwacje i zmienne, są przedstawione na tym samym wykresie, a nie z faktu, że zazwyczaj jest tu użyta dwuwymiarowa reprezentacja. Aproksymacja użyta w metodzie polega na tym, że oryginalna macierz danych jest przeliczana pod kątem największej możliwej wariancji. Na wykresie Biplotu:
obserwacje są zazwyczaj zaznaczone jako punkty
zmienne są zaznaczone jako wektory wychodzące z jednego punktu. Kąty między wektorami przedstawiają korelacje między zmiennymi
Wymiar poziomy (Rys.13) reprezentuje zmienne rozmiaru (DŁUGOŚĆ, WAGA, PRZEMIESZCZENIE). Ich ujemna relacja ze zużyciem paliwa na milę (MPG) i stosunkiem zmian biegów jest przedstawione jako wektory skierowane w przeciwnym kierunku. Wymiar pionowy pokazuje przede wszystkim zmienne kosztów napraw w umiarkowanym uzależnieniu od CENY, wielkości bagażnika i kabiny.
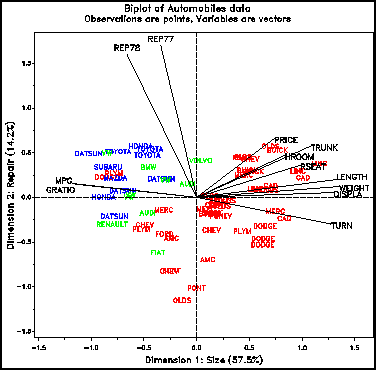 Rys.13 Dwuwymiarowy Biplot dla danych AUTO.
Rys.13 Dwuwymiarowy Biplot dla danych AUTO.